Claude Opus 4.8 vs GPT-5.5: Which One Should You Actually Use?
 If you’ve been bouncing between two browser tabs trying to decide which model deserves your subscription — or your company’s API budget — you’re not alone. Claude Opus 4.8 and GPT-5.5 are the two names everyone keeps pitting against each other, and the honest answer to “which one is better” is more interesting than a single winner.We ran both through a head-to-head benchmark across the four categories that actually matter day to day: coding, agentic tasks, knowledge, and multimodal work. The short version? It’s close. Claude edges ahead overall, 93 to 91. But the overall number hides the part that should drive your decision, which is where each model wins.Let’s break it down without the marketing fog.
If you’ve been bouncing between two browser tabs trying to decide which model deserves your subscription — or your company’s API budget — you’re not alone. Claude Opus 4.8 and GPT-5.5 are the two names everyone keeps pitting against each other, and the honest answer to “which one is better” is more interesting than a single winner.We ran both through a head-to-head benchmark across the four categories that actually matter day to day: coding, agentic tasks, knowledge, and multimodal work. The short version? It’s close. Claude edges ahead overall, 93 to 91. But the overall number hides the part that should drive your decision, which is where each model wins.Let’s break it down without the marketing fog.
The Verdict in One Line
Claude Opus 4.8 takes the overall lead at 93 vs 91 and wins three of the four categories. GPT-5.5 is not a runner-up you should dismiss, though — it’s a genuine competitor that claws back the Agentic category and matches Claude on the things people check first, like context window and input pricing.
So this isn’t a blowout. It’s a “depends on your work” situation, and I’ll show you exactly where the lines fall.
Coding: This Is Claude’s Home Turf
If you write code, or you’re paying for a model mostly to help you ship software, the decision gets easy fast.
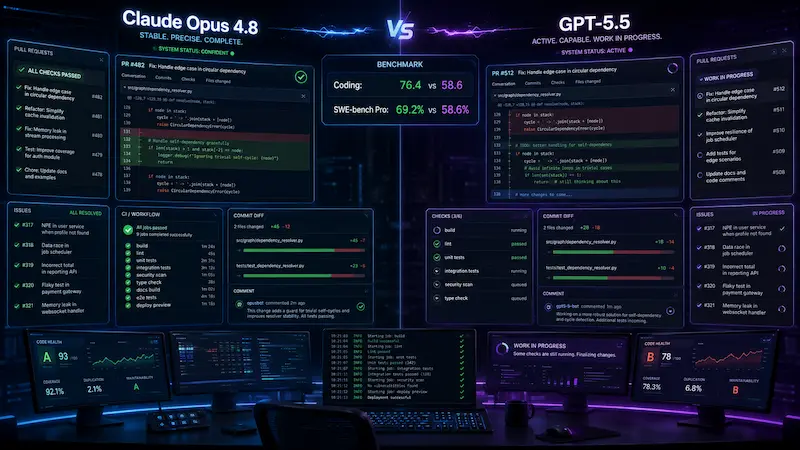
Claude Opus 4.8 wins coding 76.4 to 58.6. That’s a +17.8 gap — by far the widest margin anywhere in the comparison. To put that in plain terms: this isn’t “slightly better at clean syntax.” It’s a different tier of usefulness on real engineering work.
The clearest signal is SWE-bench Pro, the benchmark that throws actual GitHub-style issues at a model and asks it to resolve them inside a real codebase. Claude lands 69.2% against GPT-5.5’s 58.6%. Resolving real bugs in a real repo is messy, context-heavy work, and a ten-point lead there translates into fewer dead ends, fewer “almost right” patches, and less time you spend cleaning up after the model.
If coding is your primary use case, you can basically stop reading here. Claude Opus 4.8 is the pick. (If you want a deeper look at how it performs on real projects, see our best AI tools for coding guide.)
Agentic Tasks: GPT-5.5 Wins, But Barely

Now the plot twist. The one category Claude doesn’t take is Agentic — the world of tool use, multi-step workflows, and “go do this whole task for me” automation.
GPT-5.5 wins it 81.5 to 80.1. But look at that margin: +1.4. That’s about as thin as a benchmark result gets. The two models are essentially neck and neck, and GPT-5.5 nudges ahead mostly on structured tool-use and customer-workflow style tasks.
The one place GPT-5.5 shows a cleaner edge is Terminal-Bench 2.1, where it scores roughly 78.2% to Claude’s 74.6%. Worth a caveat though — terminal benchmarks are notoriously sensitive to which test harness you run them through, so I’d treat that gap as suggestive rather than settled.
Interestingly, on OSWorld-Verified (another agentic-style benchmark), Claude actually flips it back, winning 83.4% to about 78.7%. And on GDPval-AA, an Elo-style rating, Claude pulls way ahead at 1890 versus roughly 1769.
The takeaway: GPT-5.5 owns the Agentic category on paper, but it’s a coin-flip in practice. If your entire reason for choosing a model is heavy autonomous agent workflows, GPT-5.5 is a defensible choice. For almost everyone else, the gap is too small to override Claude’s wins elsewhere.
Knowledge and Reasoning: A Photo Finish
This is where the “they’re basically the same” crowd has a point.
Claude wins Knowledge 70.1 to 66.4 — a real but modest +3.7. The fascinating detail is on raw intelligence. On the Artificial Analysis Intelligence Index, the two are practically level: 61.4 versus 60.2. And on GPQA Diamond, a brutal graduate-level science benchmark, they tie outright.
What does that mean for you? If you’re using these models for research, analysis, explaining hard concepts, or general “smart assistant” work, you will not feel a dramatic difference in reasoning horsepower. Both are extremely capable. Claude’s category win comes from being steadier across a wider range of knowledge tasks rather than being radically smarter on any single one.
So if reasoning is your main need, pick based on price, ecosystem, or the other categories — because raw intelligence is close to a wash here.
Multimodal and Document Work: The Underrated Difference

Here’s the category most people skip in comparisons, and it’s the one that produced the single most lopsided benchmark result in the whole test.
Claude wins Multimodal and Grounded work 76.1 to 70.4, a solid +5.7. But the headline number lives inside it: OfficeQA Pro, which tests how well a model reasons over real documents — spreadsheets, reports, the kind of files you actually work with. Claude scores 66.2% to GPT-5.5’s 54.1%. That’s a +12.1 gap, the biggest single swing in the entire comparison after coding.
If a big chunk of your day is “read this PDF and answer questions,” “pull the numbers out of this report,” or “summarize this messy document and don’t hallucinate the figures,” that twelve-point edge is the kind of thing you’ll feel every single week. Document-grounded accuracy is unglamorous, but it’s where a lot of real knowledge work actually happens — and it’s why we rated Claude so highly in our full Claude Opus 4.8 review.
Pricing and Context: Mostly a Tie, Slight Edge to Claude
Good news for your budget: this isn’t a category where one model gouges you.
Both Claude Opus 4.8 and GPT-5.5 offer a generous 1M-token context window, so you can feed either one enormous documents or entire codebases. Input pricing is identical at $5 per million tokens.
The only difference is on output: Claude runs $25 per million tokens versus GPT-5.5’s $30. So Claude is modestly cheaper, but not by enough to swing a decision on its own. (Speed and latency weren’t reported for either model in this lane, so I won’t pretend to compare them.)
Bottom line on cost: call it a tie with a small nod to Claude. If you want to map this to your own usage, our AI cost calculator lets you plug in token volumes and see the real monthly difference.
So Which One Should You Pick?
Here’s the cheat sheet, based on the actual results rather than vibes.
Choose Claude Opus 4.8 if:
- You write code or build software (the +17.8 coding gap is the single most decisive number here)
- You work heavily with documents, spreadsheets, or grounded multimodal tasks
- You want the strongest all-around performer and a slightly lower output price
- You want the overall benchmark leader, full stop
Consider GPT-5.5 if:
- Autonomous agent and tool-use workflows are genuinely your primary use case
- You’re already deep in an ecosystem built around it and the +1.4 agentic edge tips the scale
For most people — developers, analysts, researchers, knowledge workers — Claude Opus 4.8 is the more sensible default. It wins where the gaps are wide and ties where they’re narrow. GPT-5.5’s lone category win is decided by a margin so slim it could flip on a different test harness.
Still not sure which model fits your stack, or how to roll it out across a team? That’s exactly what we do — our AI consulting services help businesses pick the right model, set it up, and get real value out of it without the trial-and-error.
Frequently Asked Questions
Which is better overall, Claude Opus 4.8 or GPT-5.5?
Claude Opus 4.8 leads the provisional leaderboard 93 to 91. The biggest single separator is OfficeQA Pro, where Claude scores 66.2% versus 54.1%.
Which is better for coding?
Claude Opus 4.8, clearly. It averages 76.4 versus 58.6 in coding, and SWE-bench Pro shows the widest separation at 69.2% versus 58.6%.
Which is better for agentic tasks?
GPT-5.5 has a slight edge, averaging 81.5 versus 80.1. But the gap is only +1.4, and Claude actually leads several individual agentic benchmarks like OSWorld-Verified and GDPval-AA.
Which is better for knowledge and multimodal work?
Claude Opus 4.8 leads both — Knowledge 70.1 vs 66.4, and Multimodal 76.1 vs 70.4, with its biggest advantage on document-grounded tasks.
Is one of them cheaper?
They cost the same on input ($5 per million tokens) and both offer a 1M-token context window. Claude is slightly cheaper on output at $25 versus $30 per million tokens.
Final Thoughts
The headline “93 vs 91” makes this look like a near-tie, and on raw intelligence it almost is. But averages flatten the story. The real picture is two strong models that pull apart exactly where it counts: Claude dominates coding and document work, GPT-5.5 holds a wafer-thin lead on agents, and everything else is close.
Pick based on what you actually do, not the overall score. If that’s coding, analysis, or document-heavy work, Claude Opus 4.8 is the safer, stronger bet. If you live inside autonomous agent workflows, GPT-5.5 earns a real look. Either way, you’re choosing between two of the best models available — and that’s a good problem to have. For more head-to-head breakdowns, browse our AI model comparisons.
Benchmark figures referenced throughout are from the Estimado-Waseem Benchmark Test (provisional ranking lane, May 2026). Terminal-Bench results are harness-sensitive; figures marked approximate are derived from reported margins.